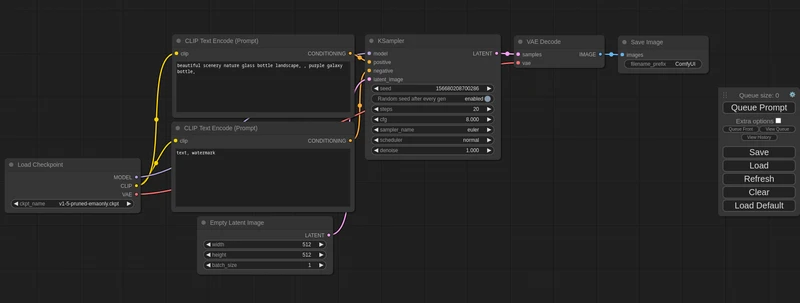
Stable Diffusion是一种潜在扩散模型(Latent Diffusion Model, LDM),它是扩散模型的一种变体。该模型旨在通过深度学习技术,将输入的文本描述转化为对应的图像。Stable Diffusion的核心思想在于,它利用文本中包含的信息作为指导,逐步将一张纯噪声的图片去噪,最终生成一张与文本信息高度匹配的图像。这种模型不仅可以用于生成全新的图像,还可以进行图像修复、风格转换等多种任务。
功能介绍:
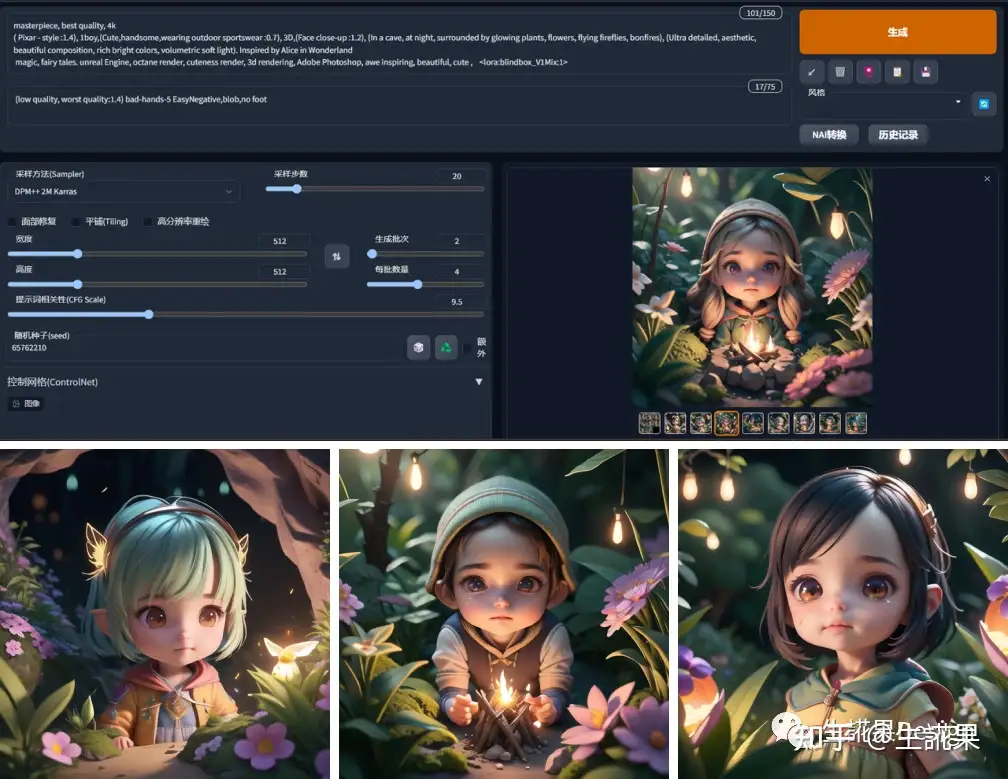
- 文本到图像生成:Stable Diffusion最主要的功能是根据用户输入的文本描述生成相应的图像。这种能力使得用户可以轻松地通过文字创作出丰富多样的视觉内容。
- 图像修复与增强:除了生成全新图像外,Stable Diffusion还可以用于图像的修复和增强。例如,它可以填补图像中的缺失部分,或者提高图像的分辨率和清晰度。
- 风格转换:用户可以通过输入特定的风格描述或参考图像,让Stable Diffusion将一张图像转换为另一种风格。这种功能在艺术创作和图像处理领域具有广泛的应用前景。
- 图生图转变:在提示词的指导下,Stable Diffusion还可以实现图生图的转变,即根据一张已有的图像和新的文本描述,生成一张新的、与文本描述相匹配的图像。
收费情况:
Stable Diffusion是一个免费开源的模型。用户可以在GitHub上找到该模型的完整源代码和文档,无需支付任何费用即可使用。这种开源模式不仅降低了用户的使用门槛,还吸引了大量的贡献者和使用者来共同优化和改进模型的功能和性能。相比之下,一些其他类似的商业模型可能需要用户付费才能使用其高级功能或更高质量的图像生成服务。