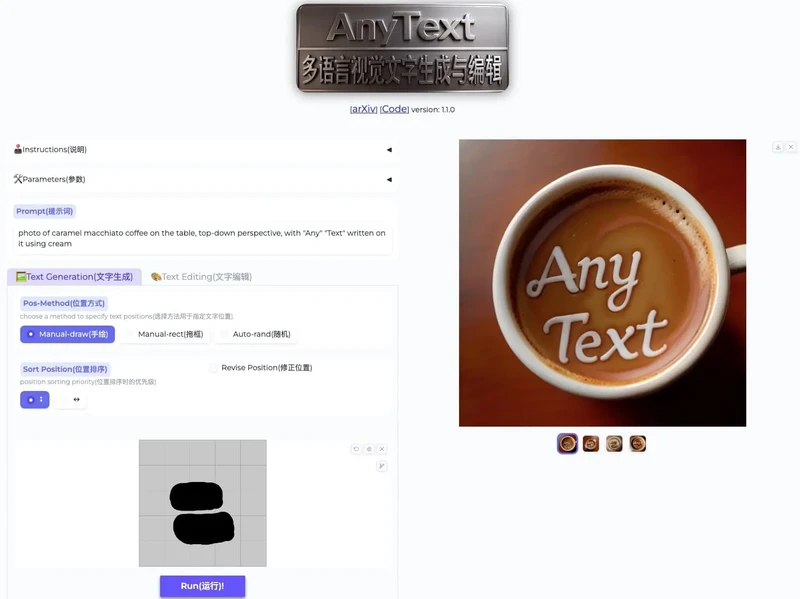
AnyText提供了文字生成和文字编辑两种模式,它能够根据提示词生成图文融合的图片,并确保文字的准确性,还支持对上传图片中的文字进行编辑后,重新生成图片。支持中文、英语、日语、韩语等多语言,适用于海报设计、Logo 设计、创意涂鸦、表情包等场景。
主要特性
- 多语言支持:AnyText能够生成多种语言的文本,包括中文、英文、日文、韩文等。
- 多行文本生成:用户可以指定在图像的多个位置生成文本。
- 变形区域书写:AnyText能够生成水平、垂直甚至曲线或不规则区域内的文本。
- 文本编辑能力:AnyText提供了修改图像中指定位置文本内容的功能,同时保持与周围文本风格的一致性。
- 即插即用:AnyText可以无缝集成到现有的扩散模型中,提供生成文本的能力。
开始使用 🚀
安装
# Install git (skip if already done)
conda install -c anaconda git
# Clone anytext code
git clone https://github.com/tyxsspa/AnyText.git
cd AnyText
# Prepare a font file; Arial Unicode MS is recommended, **you need to download it on your own**
mv your/path/to/arialuni.ttf ./font/Arial_Unicode.ttf
# Create a new environment and install packages as follows:
conda env create -f environment.yaml
conda activate anytext
推理
[推荐]:AnyText 在ModelScope和HuggingFace上发布了一个demo!您也可以通过我们的 API 服务试用 AnyText。
AnyText 包括两种模式:文本生成和文本编辑。运行下面的简单代码以在两种模式下执行推理,并验证环境是否已正确安装。
python inference.py
如果您有高级 GPU(至少 8G 内存),建议部署我们的 Demo,如下所示,其中包括使用说明、用户界面和丰富的示例。
export CUDA_VISIBLE_DEVICES=0 && python demo.py
默认使用 FP16 推理,并加载中英文翻译模型直接输入中文提示符(占用 ~4GB GPU 内存)。可以修改默认行为,因为以下命令会启用 FP32 推理并禁用翻译模型:
export CUDA_VISIBLE_DEVICES=0 && python demo.py --use_fp32 --no_translator
如果使用 FP16 且未使用翻译模型(或将其加载到 CPU 上,请参阅此处),则生成单个 512x512 图像将占用 ~7.5GB 的 GPU 内存。 此外,其他字体文件也可以使用(尽管结果可能不是最佳的):
export CUDA_VISIBLE_DEVICES=0 && python demo.py --font_path your/path/to/font/file.ttf
您还可以加载指定的 AnyText 检查点:
export CUDA_VISIBLE_DEVICES=0 && python demo.py --model_path your/path/to/your/own/anytext.ckpt