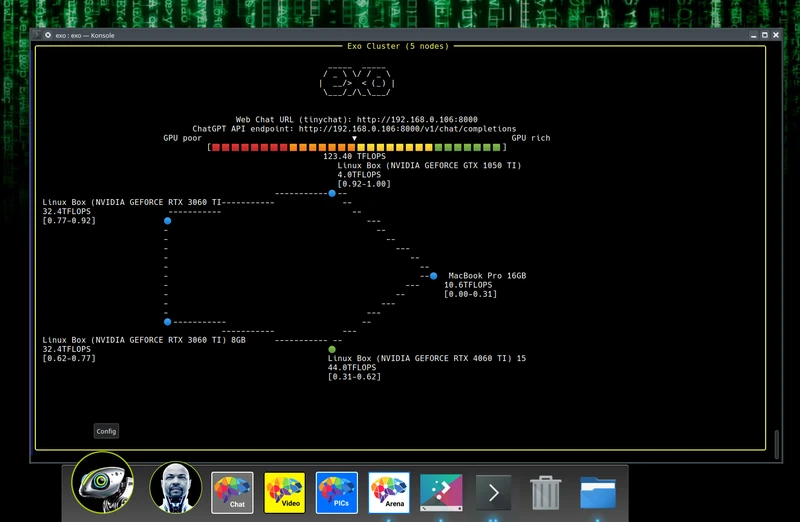
该项目能够利用日常家用设备(如手机、笔记本电脑、台式机等)来搭建家庭 AI 集群。它通过整合现有的设备,无需昂贵硬件,即可构建一个低成本、可扩展的 GPU 计算集群,支持动态模型分区、自动发现设备、ChatGPT API、P2P 连接和多种推理引擎。
忘记昂贵的 NVIDIA GPU,将您现有的设备统一到一个强大的 GPU 中:iPhone、iPad、Android、Mac、Linux,几乎任何设备!
主要功能
-
广泛的模型支持:exo 支持不同的模型,包括 LLaMA(MLX 和 tinygrad)、Mistral、LlaVA、Qwen 和 Deepseek。
-
动态模型分区:EXO 根据当前网络拓扑和可用的设备资源对模型进行最佳拆分。这使您能够运行比在任何单个设备上更大的模型。
-
自动设备发现:EXO 将使用可用的最佳方法自动发现其他设备。无需手动配置。
-
兼容 ChatGPT 的 API:exo 提供了一个兼容 ChatGPT 的 API 来运行模型。使用 exo 在您自己的硬件上运行模型只需在应用程序中进行一行更改。
-
设备相等:与其他分布式推理框架不同,exo 不使用主工作架构。相反,exo 设备连接 p2p。只要设备连接到网络中的某个位置,它就可以用于运行模型。Exo 支持不同的分区策略,以跨设备拆分模型。默认分区策略是环形内存加权分区。这将在一个环中运行推理,其中每个设备运行与设备内存成比例的模型层数。
安装使用
当前推荐的安装 exo 的方法是 使用源码安装。
先决条件
-
Python>=3.12.0 是必需的,因为以前版本中的 asyncio 存在问题。
-
Linux(带 NVIDIA 卡):
- NVIDIA 驱动程序(使用
nvidia-smi) - CUDA (https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#cuda-cross-platform-installation) (使用
nvcc --version) - cuDNN (https://developer.nvidia.com/cudnn-downloads) (使用链接进行测试)
- NVIDIA 驱动程序(使用
硬件要求
-
运行 exo 的唯一要求是在所有设备上有足够的内存,以将整个模型放入内存中。例如,如果您运行的是 llama 3.1 8B (fp16),则所有设备都需要 16GB 内存。以下任何配置都可以使用,因为它们的总内存都超过 16GB:
- 2 个 8GB M3 MacBook Air
- 1 x 16GB NVIDIA RTX 4070 Ti 笔记本电脑
- 2 个 Raspberry Pi 400,每个 4GB RAM(在 CPU 上运行)+ 1 个 8GB Mac Mini
-
exo 旨在运行在具有异构功能的设备上。例如,您可以让一些设备具有强大的 GPU,而另一些设备具有集成的 GPU 甚至 CPU。添加功能较弱的设备会减慢单个推理延迟,但会增加集群的整体吞吐量。
从源码安装
git clone https://github.com/exo-explore/exo.git
cd exo
pip install -e .
# alternatively, with venv
source install.sh
故障 排除
- 如果在 Mac 上运行,MLX 会提供包含故障排除步骤的安装指南。
性能
- 用户凭经验发现,有许多方法可以提高 Apple Silicon Mac 的性能:
- 升级到最新版本的 MacOS 15。
- 跑。这将运行命令以优化 Apple Silicon Mac 上的 GPU 内存分配。
./configure_mlx.sh
在多个 MacOS 设备上的使用示例
设备 1:
exo
设备 2:
exo
就是这样!无需配置 - exo 将自动发现其他设备。
exo 在 http://localhost:52415 上启动了一个类似 ChatGPT 的 WebUI(由 tinygrad tinychat 提供支持)
对于开发人员,exo 还会在 http://localhost:52415/v1/chat/completions 上启动一个与 ChatGPT 兼容的 API 端点。curl 的示例:
Llama 3.2 3B:
curl http://localhost:52415/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama-3.2-3b",
"messages": [{"role": "user", "content": "What is the meaning of exo?"}],
"temperature": 0.7
}'
Llama 3.1 405B:
curl http://localhost:52415/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama-3.1-405b",
"messages": [{"role": "user", "content": "What is the meaning of exo?"}],
"temperature": 0.7
}'
Llava 1.5 7B(视觉语言模型):
curl http://localhost:52415/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llava-1.5-7b-hf",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What are these?"
},
{
"type": "image_url",
"image_url": {
"url": "http://images.cocodataset.org/val2017/000000039769.jpg"
}
}
]
}
],
"temperature": 0.0
}'
在多个异构设备 (MacOS + Linux) 上的示例用法
设备 1 (MacOS):
exo --inference-engine tinygrad
这里我们明确告诉 exo 使用 tinygrad 推理引擎。
设备 2 (Linux):
exo
Linux 设备将自动默认使用 tinygrad 推理引擎。
你可以在这里阅读特定于 tinygrad 的环境变量。例如,您可以通过指定 tinygrad 来配置 tinygrad 以使用 cpu。CLANG=1
示例:在单台设备上使用 “exo run” 命令
exo run llama-3.2-3b
使用自定义提示符:
exo run llama-3.2-3b --prompt "What is the meaning of exo?"
模型存储
默认情况下,模型存储在 中。~/.cache/huggingface/hub
您可以通过设置 env var.HF_HOME
调试
使用 DEBUG 环境变量 (0-9) 启用调试日志。
DEBUG=9 exo
特别是对于 tinygrad 推理引擎,有一个单独的 DEBUG 标志可用于启用调试日志 (1-6)。TINYGRAD_DEBUG
TINYGRAD_DEBUG=2 exo
格式
我们使用 yapf 来格式化代码。要格式化代码,请首先安装格式化要求:
pip3 install -e '.[formatting]'
然后运行格式化脚本:
python3 format.py ./exo