Moondream开源项目是一个拥有 16 亿参数的视觉AI模型,它采用了 SigLIP、Phi-1.5 技术和 LLaVa 训练数据集,能够在任何平台运行。它致力于通过深度学习和计算机视觉技术实现“看图说话”的神奇功能。它不仅能精准捕捉并解析图像中的关键细节与场景信息,还能将这些视觉元素转化成连贯且富有情感色彩的语言描述,为用户带来全新的交互体验。该模型突破了传统图文转换工具的局限性,开启了图像内容自动转述的新篇章。
Moondream不仅仅是"另一个"人工智能AI。它也是一个工具,旨在理解各种输入,包括口语、书面文本和视觉内容。无论你是希望将AI集成到应用程序中的开发人员,还是渴望了解最新技术的学生,甚至仅仅是AI爱好者,Moondream的多功能性都可以将你所需的各种类型的信息转换为文本输出。
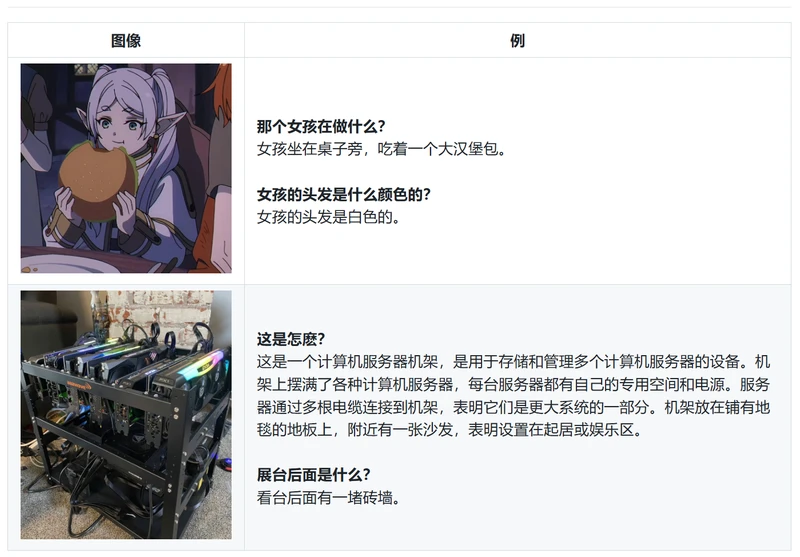
主要功能:
-
图像转文字解读: Moondream能够深入理解图像中的物体、动作、情境关系等复杂视觉元素,并以自然语言的形式详尽阐述图像背后的故事,使静态图片拥有动态讲述的能力。
-
上下文情境理解: 在处理图像时,Moondream具备上下文理解能力,能结合文化背景和常识推理,生成符合逻辑且富有趣味性的文字说明,进一步提升图像叙述的真实性和生动性。
安装和使用:
使用transformers(推荐)
pip install transformers einops
from transformers import AutoModelForCausalLM, AutoTokenizer
from PIL import Image
model_id = "vikhyatk/moondream2"
revision = "2024-08-26"
model = AutoModelForCausalLM.from_pretrained(
model_id, trust_remote_code=True, revision=revision
)
tokenizer = AutoTokenizer.from_pretrained(model_id, revision=revision)
image = Image.open('<IMAGE_PATH>')
enc_image = model.encode_image(image)
print(model.answer_question(enc_image, "Describe this image.", tokenizer))
模型会定期更新,因此我们建议将模型版本固定到 特定版本,如上所示。
要在文本模型上启用 Flash Attention,请在实例化模型时传入。attn_implementation="flash_attention_2"
model = AutoModelForCausalLM.from_pretrained(
model_id, trust_remote_code=True, revision=revision,
torch_dtype=torch.float16, attn_implementation="flash_attention_2"
).to("cuda")
还支持批量推理。
answers = moondream.batch_answer(
images=[Image.open('<IMAGE_PATH_1>'), Image.open('<IMAGE_PATH_2>')],
prompts=["Describe this image.", "Are there people in this image?"],
tokenizer=tokenizer,
)
使用软件仓
克隆此存储库并安装依赖项。
pip install -r requirements.txt
sample.py提供用于运行模型的 CLI 接口。如果未提供参数,该脚本将允许您以交互方式提问。--prompt
python sample.py --image [IMAGE_PATH] --prompt [PROMPT]
使用脚本为模型启动 Gradio 接口。gradio_demo.py
python gradio_demo.py
webcam_gradio_demo.py为模型提供了一个 Gradio 接口,该接口使用网络摄像头作为输入并实时执行推理。
python webcam_gradio_demo.py


