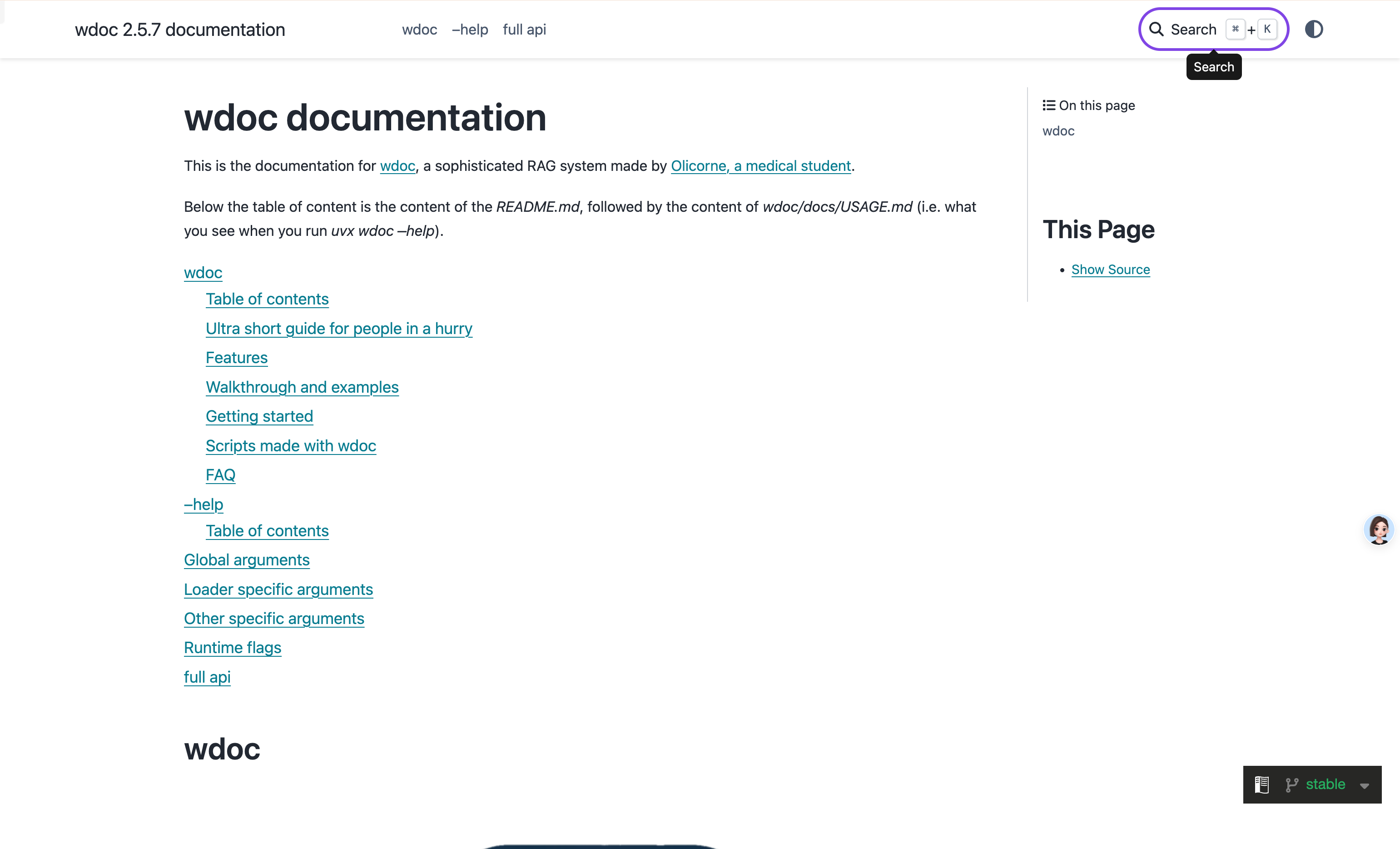
Spark-TTS 完全基于 [Qwen2.5]构建,无需使用流匹配等额外生成模型。它无需依赖单独的模型来生成声学特征,而是直接从 [LLM] 预测的代码中重建音频。这种方法简化了流程,提高了效率并降低了复杂性。
上传任意10秒语音片段,瞬间复刻声纹特征!无论是跨语种的中英混说,还是模仿特定语调,通通零样本实现。自媒体博主惊呼:“我的百万声库要失业了!”
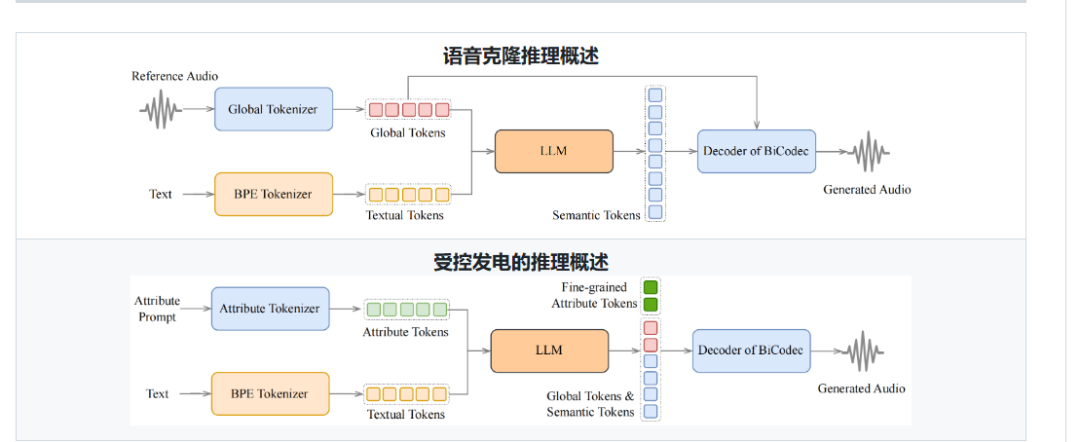
- 简单高效:Spark-TTS 完全基于 Qwen2.5 构建,无需额外的生成模型,如流程匹配。它不依赖单独的模型来生成声学特征,而是直接从 LLM 预测的代码中重建音频。这种方法简化了流程,提高了效率并降低了复杂性。
- 高质量语音克隆:支持零样本语音克隆,这意味着即使没有针对该语音的特定训练数据,它也可以复制说话者的语音。这是跨语言和代码切换场景的理想选择,允许在语言和语音之间无缝转换,而无需对每种语言和语音进行单独培训。
- 双语支持:支持中英文,能够针对跨语言和换码场景进行零镜头语音克隆,使模型能够以高自然度和准确性合成多种语言的语音。
- 语音生成可控:支持通过调整性别、音调、语速等参数创建虚拟说话人。
安装
克隆和安装
以下是在 Linux 上安装的说明。如果您使用的是 Windows,请参阅 Windows 安装指南。
- 克隆存储库
git clone https://github.com/SparkAudio/Spark-TTS.git
cd Spark-TTS
- 安装 Conda:请参阅 https://docs.conda.io/en/latest/miniconda.html
- 创建 Conda 环境:
conda create -n sparktts -y python=3.12
conda activate sparktts
pip install -r requirements.txt
# If you are in mainland China, you can set the mirror as follows:
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
模型下载
通过 python 下载:
from huggingface_hub import snapshot_download
snapshot_download("SparkAudio/Spark-TTS-0.5B", local_dir="pretrained_models/Spark-TTS-0.5B")
通过 git clone 下载:
mkdir -p pretrained_models
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/SparkAudio/Spark-TTS-0.5B pretrained_models/Spark-TTS-0.5B
基本用法
您只需使用以下命令运行演示即可:
cd example
bash infer.sh
或者,您也可以在命令行中直接执行以下命令进行推理:
python -m cli.inference \
--text "text to synthesis." \
--device 0 \
--save_dir "path/to/save/audio" \
--model_dir pretrained_models/Spark-TTS-0.5B \
--prompt_text "transcript of the prompt audio" \
--prompt_speech_path "path/to/prompt_audio"
可选方法
有关其他 CLI 和 Web UI 方法,包括替代实现和扩展功能,您可以参考:
运行
Nvidia Triton 推理服务
我们现在为使用 Nvidia Triton 和 TensorRT-LLM 部署 Spark-TTS 提供了参考。下表显示了单个 L20 GPU 的基准测试结果,使用 26 个不同的 prompt_audio/target_text 对(总共 169 秒的音频):
| 型 | 注意 | 并发 | 平均延迟 | RTF |
|---|---|---|---|---|
| 火花-TTS-0.5B | 代码提交 | 1 | 876.24 毫秒 | 0.1362 |
| 火花-TTS-0.5B | 代码提交 | 2 | 920.97 毫秒 | 0.0737 |
| 火花-TTS-0.5B | 代码提交 | 4 | 1611.51 毫秒 | 0.0704 |
有关更多信息,请参阅 runtime/triton_trtllm/README.md 中的详细说明。
实战演习
Spark-TTS 的核心功能是将文本转为语音,以下是具体操作流程:
1. 使用预训练模型生成语音
-
准备文本:创建一个简单的文本文件(如
input.txt),写入需要转换的文本,例如:“你好,这是一个测试语音。” -
运行脚本:假设仓库提供了一个
generate.py脚本(具体文件名以实际仓库为准),在终端输入: 复制复制复制复制复制复制复制python generate.py --input input.txt --output output.wav -
参数说明:
--input:指定输入文本文件路径。--output:指定生成的语音文件保存路径(如output.wav)。- 如果脚本支持,可添加
--model参数选择预训练模型,或--voice参数调整声音风格。
-
结果:运行后,你会在指定路径找到生成的
output.wav文件,用音频播放器打开即可听到效果。
2. 训练自定义模型
-
准备数据集:你需要提供文本和对应的音频数据。数据格式通常是
.txt文件(文本)和.wav文件(音频),建议参考仓库中的README.md或示例文件夹。 -
配置参数:编辑配置文件(可能是
config.json或类似文件),设置训练参数,如学习率、批次大小等。如果没有配置文件,直接在脚本中修改参数。 -
启动训练:运行训练脚本,例如: 复制复制复制复制复制复制
python train.py --data_path ./dataset --output_model my_model -
训练过程:根据数据量和硬件性能,训练可能需要数小时甚至几天。完成后,你会得到一个新的模型文件(如
my_model.pth)。 -
使用新模型:将训练好的模型路径传入生成脚本:
python generate.py --input input.txt --model my_model.pth --output custom_output.wav
3. 调整语音风格
-
如果 Spark-TTS 支持多风格输出(需查看代码或文档确认),可以通过参数调整语速、音调等。例如:
python generate.py --input input.txt --speed 1.2 --pitch 0.8 --output styled_output.wav -
参数说明:
--speed:语速,1.0 为正常速度,大于 1.0 加快,小于 1.0 减慢。--pitch:音调,值越高音调越高,反之越低。
-
效果验证:生成后试听,逐步调整参数直到满意。
操作流程实例
假设你想将一段中文文本转为女性语音:
-
创建
test.txt,写入:“今天天气很好,我们去公园散步吧。” -
运行命令:
python generate.py --input test.txt --voice female --output park.wav -
检查
park.wav,确认语音是否自然流畅。 -
如果不满意,尝试调整参数或训练新模型。