这是一个高效易用的大型语言模型推理引擎,专为解决推理速度慢、资源利用率低等问题而设计。它基于 PyTorch 和 CUDA,并结合内存优化算法(PagedAttention)、计算图优化和模型并行技术,大幅降低 GPU 内存占用,并充分利用多 GPU 资源提升推理性能。同时,vLLM 与 HF 模型无缝兼容。支持在 GPU、CPU、TPU 等多种硬件平台上高效运行,适用于实时问答、文本生成和推荐系统等场景。
主要功能
- 最先进的服务吞吐量
- 使用 PagedAttention 高效管理注意力键和值内存
- 对传入请求进行连续批处理
- 使用 CUDA/HIP 图形快速执行模型
- 量化:GPTQ 、 AWQ 、 INT4 、 INT8 和 FP8 。
- 优化 CUDA 内核,包括 FlashAttention 和 FlashInfer 的集成。
- 推测解码
- 分块预填充
vLLM 非常灵活且易于使用:
- 与流行的 Hugging Face 型号无缝集成
- 使用各种解码算法(包括并行采样、光束搜索等)实现高吞吐量服务
- Tensor 并行和 Pipeline 并行支持分布式推理
- 流式处理输出
- OpenAI 兼容 API 服务器
- 支持 NVIDIA GPU、AMD CPU 和 GPU、INTEL CPU 和 GPU、POWERPC CPU、TPU 和 AWS Neuron。
- 前缀缓存支持
- Multi-lora 支持
vLLM 无缝支持 HuggingFace 上最流行的开源模型,包括:
- 类似 transformer 的 LLM(例如 Llama)
- 专家级 LLM 的混合物(例如 Mixtral、Deepseek-V2 和 V3)
- 嵌入模型(例如 E5-Mistral)
- 多模态 LLM(例如 LLaVA)
安装和使用
先决条件
- 操作系统: Linux
- Python:3.9 – 3.12
安装
如果您使用的是 NVIDIA GPU,则可以直接使用 pip 安装 vLLM。 建议使用 conda 来创建和管理 Python 环境。
$ conda create -n myenv python=3.10 -y
$ conda activate myenv
$ pip install vllm
注意
对于非 CUDA 平台,请参阅此处有关如何安装 vLLM 的具体说明。
离线批量推理
安装 vLLM 后,您可以开始为输入提示列表生成文本(即离线批量推理)。请参阅示例脚本: examples/offline_inference.py
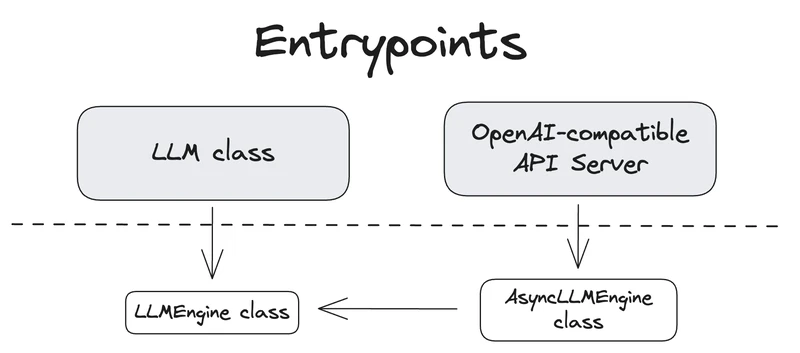
此示例的第一行导入类 和 :
- 是使用 vLLM 引擎运行离线推理的主类。
- 指定采样过程的参数。
from vllm import LLM, SamplingParams
下一节定义用于文本生成的输入提示和采样参数的列表。采样温度设置为 ,原子核采样概率设置为 。您可以在此处找到有关采样参数的更多信息。0.80.95
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
该类初始化 vLLM 的引擎和 OPT-125M 模型以进行离线推理。可在此处找到支持的模型列表。
llm = LLM(model="facebook/opt-125m")
注意
默认情况下,vLLM 从 HuggingFace 下载模型。如果要使用 ModelScope 中的模型,请在初始化引擎之前设置环境变量。VLLM_USE_MODELSCOPE
现在,有趣的部分!输出是使用 生成的。它将输入提示添加到 vLLM 引擎的等待队列中,并执行 vLLM 引擎以生成具有高吞吐量的输出。输出以对象列表的形式返回,其中包括所有输出标记。llm.generateRequestOutput
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
OpenAI 兼容服务器
vLLM 可以部署为实现 OpenAI API 协议的服务器。这使得 vLLM 可以用作使用 OpenAI API 的应用程序的直接替代品。 默认情况下,它在 启动服务器。您可以使用 和 arguments 指定地址。该服务器目前一次托管一个模型,并实现列表模型、创建聊天完成和创建完成终端节点等终端节点。http://localhost:8000--host--port
执行以下命令,启动模型为 Qwen2.5-1.5B-Instruct 的 vLLM 服务器。
$ vllm serve Qwen/Qwen2.5-1.5B-Instruct
注意
默认情况下,服务器使用存储在 tokenizer 中的预定义聊天模板。 您可以在此处了解如何覆盖它。
此服务器可以采用与 OpenAI API 相同的格式进行查询。例如,要列出模型:
$ curl http://localhost:8000/v1/models
您可以传入 argument 或 environment 变量,使服务器能够检查 header 中的 API key。--api-keyVLLM_API_KEY
使用 vLLM 的 OpenAI 补全 API
服务器启动后,您可以使用输入提示查询模型:
$ curl http://localhost:8000/v1/completions \
$ -H "Content-Type: application/json" \
$ -d '{
$ "model": "Qwen/Qwen2.5-1.5B-Instruct",
$ "prompt": "San Francisco is a",
$ "max_tokens": 7,
$ "temperature": 0
$ }'
由于此服务器与 OpenAI API 兼容,因此您可以将其用作任何使用 OpenAI API 的应用程序的直接替代品。例如,查询服务器的另一种方法是通过 Python 包:openai
from openai import OpenAI
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
completion = client.completions.create(model="Qwen/Qwen2.5-1.5B-Instruct",
prompt="San Francisco is a")
print("Completion result:", completion)
更详细的客户端示例可以在这里找到: examples/openai_completion_client.py
使用 vLLM 的 OpenAI 聊天补全 API
vLLM 还旨在支持 OpenAI 聊天完成 API。聊天界面是一种与模型通信的更加动态的交互式方式,允许来回交换,这些交换可以存储在聊天历史记录中。这对于需要上下文或更详细解释的任务非常有用。
您可以使用 create chat completion 终端节点与模型交互:
$ curl http://localhost:8000/v1/chat/completions \
$ -H "Content-Type: application/json" \
$ -d '{
$ "model": "Qwen/Qwen2.5-1.5B-Instruct",
$ "messages": [
$ {"role": "system", "content": "You are a helpful assistant."},
$ {"role": "user", "content": "Who won the world series in 2020?"}
$ ]
$ }'
或者,您可以使用 Python 包:openai
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="Qwen/Qwen2.5-1.5B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."},
]
)
print("Chat response:", chat_response)