AI开源
AI实验室
AI期刊
关于
更多...
小众AI
AI开源
AI实验室
AI期刊
关于
Ai应用
C++
Golang
Java
Javascript
Jupyter
Python
Rust
Typescript
内容检测
图像处理
文档处理
智能助手
智能搜索
模型工具
行业应用
行业引用
视频处理
语言处理
辅助编程
音频处理
AI开源软件
Ai应用
C++
Golang
Java
Javascript
Jupyter
Python
Rust
Typescript
内容检测
图像处理
文档处理
智能助手
智能搜索
模型工具
行业应用
行业引用
视频处理
语言处理
辅助编程
音频处理
AI开源软件
>
Python
Oumi - 一站式构建基础模型
Oumi 是一个完全开源的平台,可简化基础模型的整个生命周期 - 从数据准备和训练到评估和部署。
story-flicks - AI大模型一键生成高清故事短视频
可以输入一个故事主题,使用大语言模型生成故事视频,视频中包含大模型生成的图片、故事内容,以及音频和字幕信息。
pptx2md - 将PPT文件转换成Markdown
将 Powerpoint pptx 文件转换为 markdown 的工具。
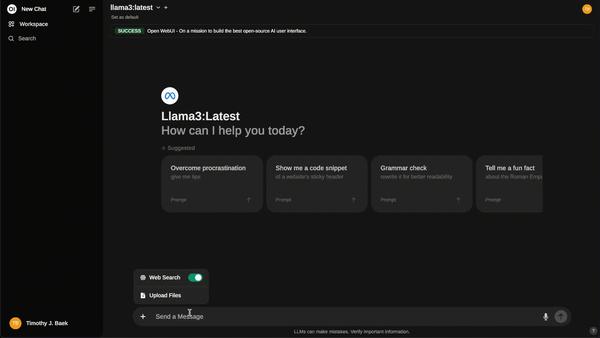
open-webui - 用户友好的 AI 界面
功能强大、用户友好的自托管 AI 平台,支持完全离线运行。它集成了多种大型语言模型运行器,如 Ollama 和 OpenAI 兼容的 API,支持网页搜索、本地 RAG 集成、权限管理、适配移动端、Markdown 和 LaTeX 等功能。
aisuite - 一个接口调用多个大模型
`aisuite`使开发人员能够通过标准化接口轻松使用多个 LLM。使用类似于 OpenAI 的界面,可以轻松地与最流行的 LLM 进行交互并比较结果。它是 python 客户端库的精简包装器,允许创建者无缝交换和测试来自不同 LLM 提供程序的响应,而无需更改其代码。如今,该库主要专注于聊天完成。我们将在不久的将来将其扩展到更多使用案例。
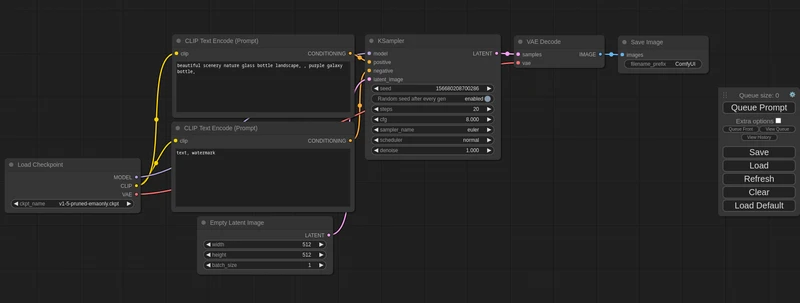
ComfyUI - 不仅是一个用户界面
为Windows和macOS设计的桌面客户端,它提供了一键安装的便利性,并拥有全新的用户界面。用户可以通过加入等待名单来获得早期访问权限。这款软件的主要优点在于它的易用性和现代化的界面设计,旨在提高用户的工作效率。
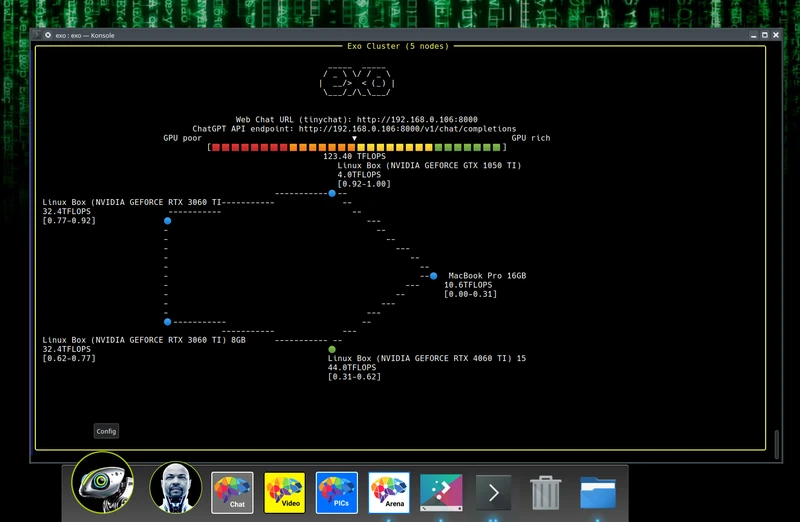
exo - 利用家用设备打造低成本的 AI 集群
够利用日常家用设备(如手机、笔记本电脑、台式机等)来搭建家庭 AI 集群。它通过整合现有的设备,无需昂贵硬件,即可构建一个低成本、可扩展的 GPU 计算集群,支持动态模型分区、自动发现设备、ChatGPT API、P2P 连接和多种推理引擎。
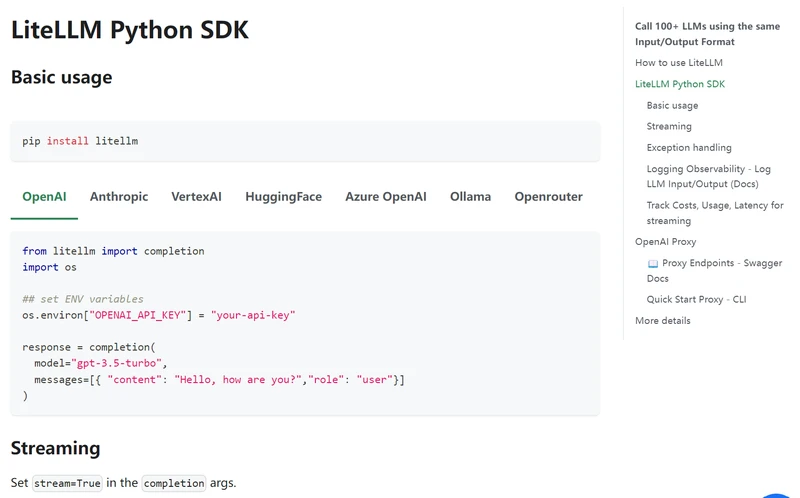
litellm - 简化大模型 API 调用的工具
将各种 AI 大模型和服务的接口,统一转换成 OpenAI 的格式,简化了在不同 AI 服务/大模型切换和管理的工作。此外,它还支持设置预算、限制请求频率、管理 API Key 和配置 OpenAI 代理服务器等功能。
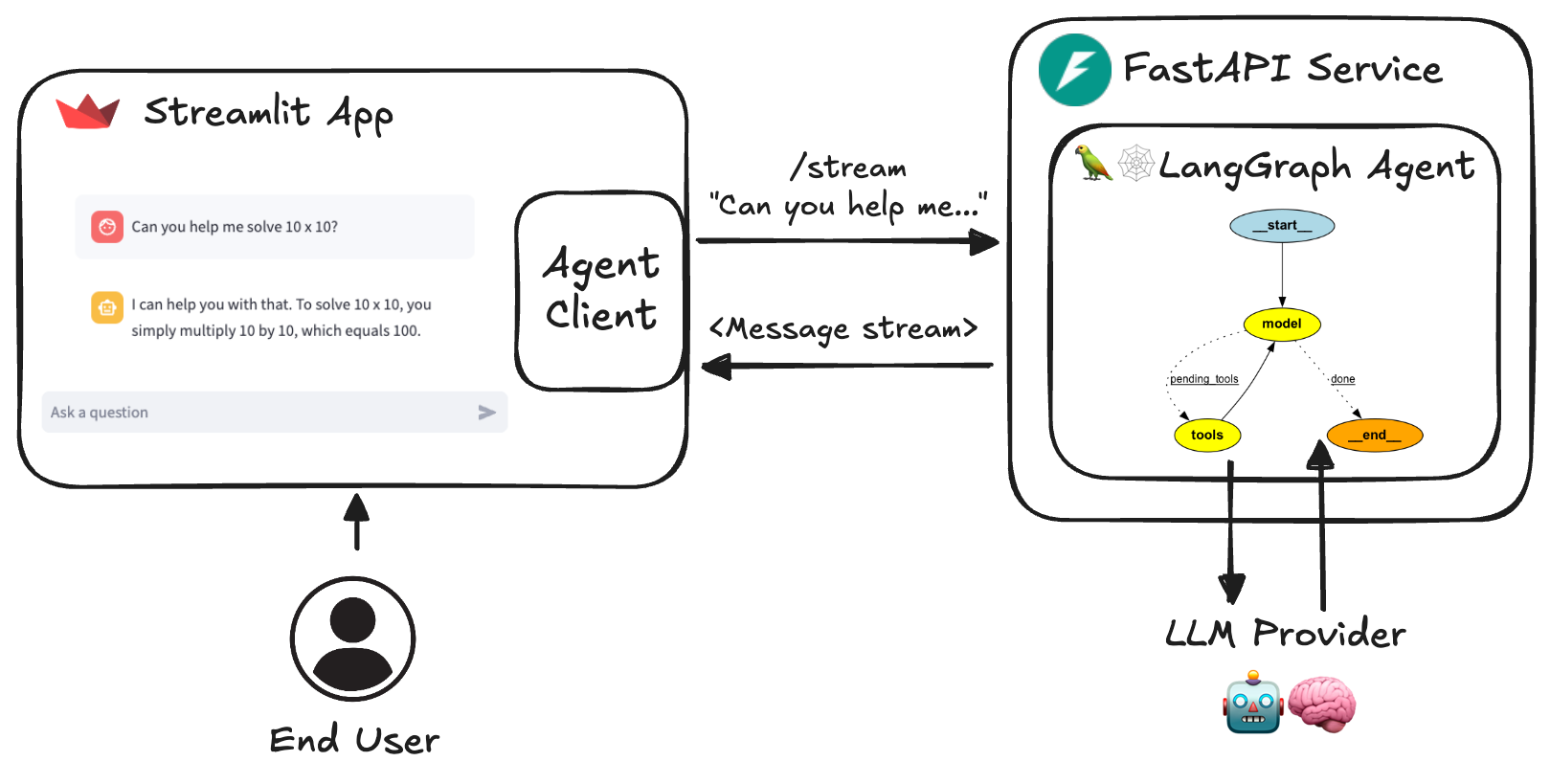
agent-service-toolkit - 轻量级的 AI 代理开发框架
帮助开发者用 Python 快速搭建和运行基于 LangGraph 框架的 AI 代理服务。它结合 FastAPI、Streamlit 和 Pydantic 等技术栈,提供了用户界面、自定义 Agent、流式传输等功能,并集成了内容审核(LlamaGuard)和用户反馈机制(LangSmith),极大地简化了 AI Agent 应用的开发和优化过程。
gptme - 终端中的个人 AI 助手
终端中的个人 AI 助手,带有工具,因此它可以:使用终端、运行代码、编辑文件、浏览 Web、使用视觉等等; 通过简单但功能强大的 CLI 协助各种知识工作,尤其是编程。
LivePortrait - 让肖像栩栩如生
通过输入静态肖像照片,LivePortrait 能够实时生成动态的肖像动画,使静态图像“活”起来。用户可以通过摄像头或手动输入来控制生成动画中的面部表情,如微笑、眨眼、皱眉等。
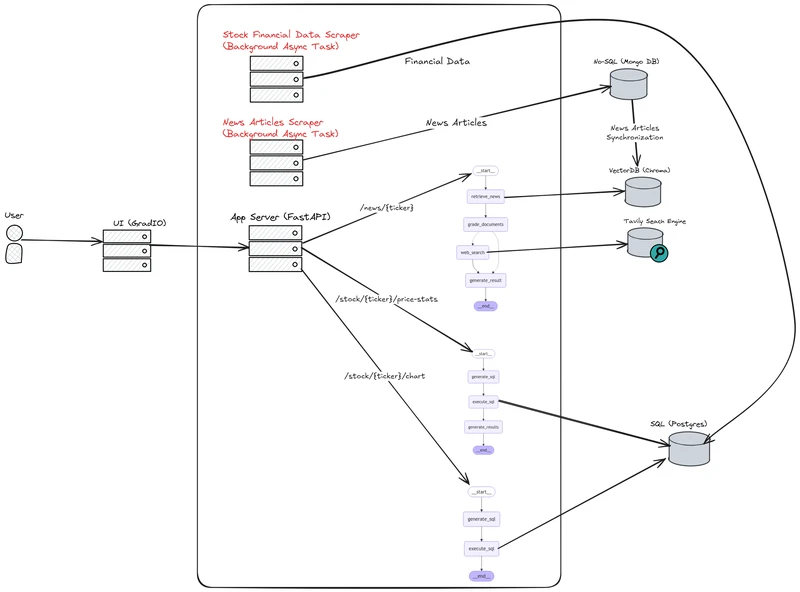
stocks-insights-ai-agent - AI驱动的股票分析工具
使用 Agentic Retrieval-Augmented Generation (RAG) 工作流程从与特定公司和更广泛的股票市场相关的新闻和财务数据中提取见解。它利用大型语言模型 (LLM)、ChromaDB 作为向量数据库、LangChain、LangChain 表达式语言 (LCEL) 和 LangGraph 来提供全面的分析。
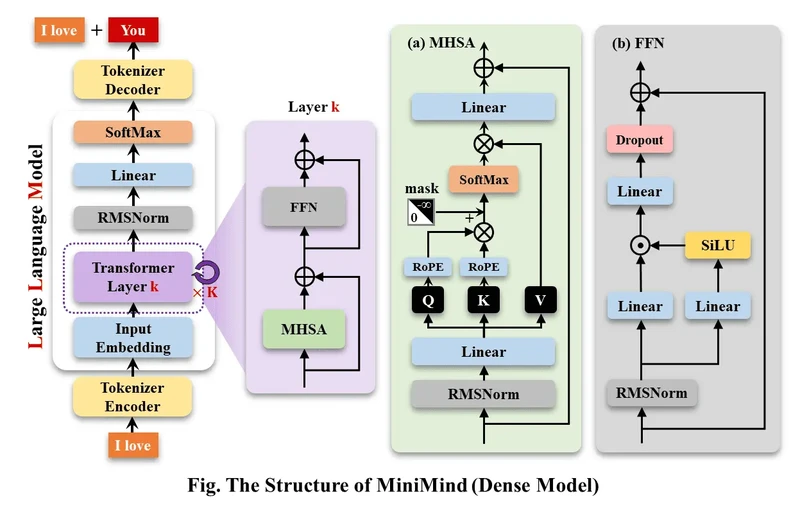
minimind - 从零开始训练小型语言模型
一个微型语言模型的实现,更是一份入门 LLM 的教程,旨在降低学习和上手 LLM 的门槛 。它提供了从数据预处理到模型训练、微调和推理的全流程代码和教程。最小模型仅 0.02B 参数,可在普通 GPU 上轻松运行。
AstrBot - 多平台 LLM 聊天机器人及开发框架
AstrBot 是一个松耦合、异步、支持多消息平台部署、具有易用的插件系统和完善的大语言模型(LLM)接入功能的聊天机器人及开发框架。
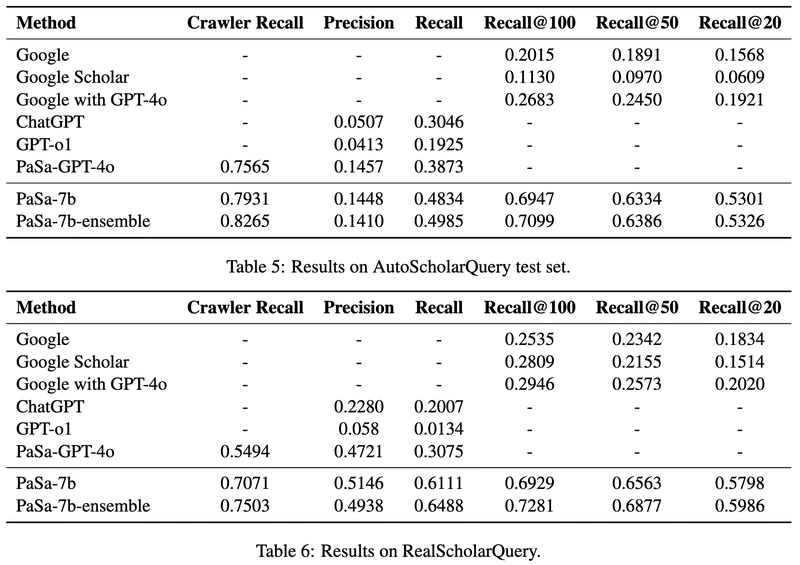
PaSa - 大型语言模型提供支持的高级论文搜索代理
一种由大型语言模型提供支持的高级 PaperSearch 代理。PaSa 可以自主做出一系列决策,包括调用搜索工具、阅读论文和选择相关参考文献,最终为复杂的学术查询获得全面准确的结果。
««
«
2
3
4
5
6
»
»»